Tree-structure segmentation for logistic regression
N.B.: ce post s’inspire librement de mon manuscrit de thèse.
In Credit Scoring, we usually learn “expert” logistic regression models on separate “segments” of clients arranged in a tree. Its more theoretical justification is similar to that of quantization, which is to achieve a good bias-variance trade-off of the predictive task. Here again, the resulting segmentation and scorecards therein can be viewed as a single model for the whole population. In the next section, we give some industrial context to the problem which is followed in Section 1.2 by a literature review. Section 1.3 reinterprets this problem, as advertised, as a model selection problem for which a specific approach is designed in subsequent sections.
Introduction
Context
As was emphasized in all previous articles, logistic regression is the building block of a scorecard predicting the creditworthiness of an applicant and partly automating the acceptance / rejection mechanism. However, estimating logistic regression coefficients means that training data \((\boldsymbol{\mathbf{x}},\boldsymbol{\mathbf{y}})\) is available. This is not the case when a new product, e.g. smartphone leasing, is added to the acceptance system. On a practical note, some other previously learnt scorecard may not be applicable on this new market because the same information is not asked to applicants, e.g. marital status, because given the low amounts at stake, it was decided to collect the fewest data possible, to make the process as simple and quick as possible. On a more theoretical note, it is probable that applicants to smartphone leasing are not stemming from the same data generating mechanism \(\boldsymbol{X},Y \sim p\) as any other previous applicants (i.e. on other markets). Put it another way, the possibility of having several logistic regression scorecards on sub-populations of the total portfolio allows to have more flexibility, and thus it potentially reduces model bias.
For these reasons, several industries, among which Credit Scoring, rely on several “weak learners” such as logistic regression, arranged in a tree. Such decision process is illustrated on Figure [1]. This tree structure and the vocabulary of “weak learners” would indicate a use-case of Mixtures of Experts [1] or aggregation / ensemble methods [2] respectively. However, these fuzzy methods imply that all applicants are scored by all scorecards, which is obviously neither desirable (for interpretation purposes) nor feasible (since available features differ).
The next section illustrates how such a structure is achieved using CACF’s in-house practices.
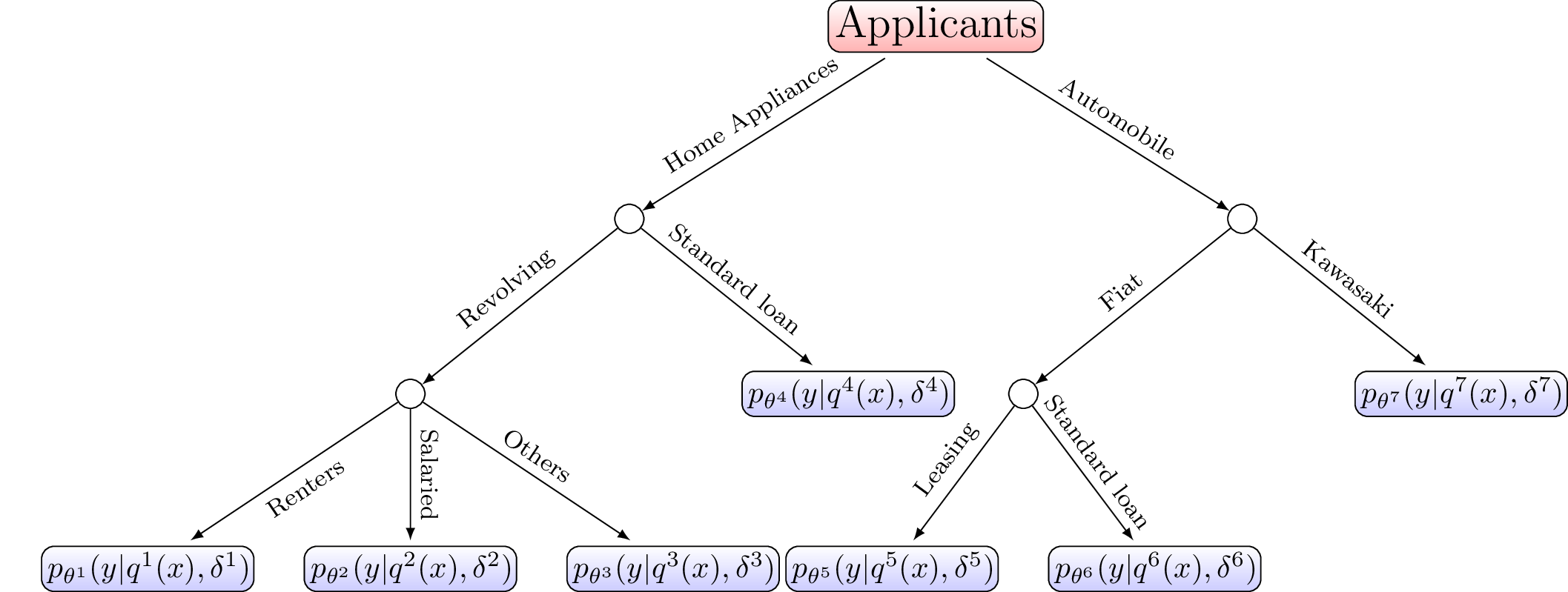
In-house ad hoc practice
Credit Scoring practitioners are often asked by the management to “locally” study the decision process displayed on Figure [1] by e.g. merging branches (Standard loans and Leasing for Fiat) or conversely to separate sub-populations by splitting a leaf (Kawasaki into Standard loans and Leasing). To do so, they resort to simple unsupervised generative “clustering” techniques, such as PCA and its refinements on categorical or mixed data (MCA or FAMD resp.) which are described hereafter, used to represent the data on the two first principal axes, and derive “clusters” from separated point clouds.
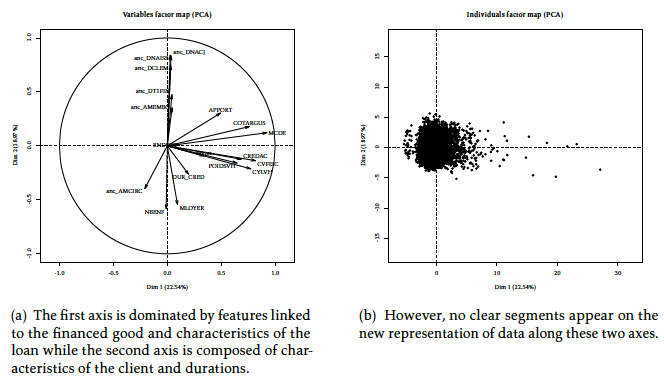
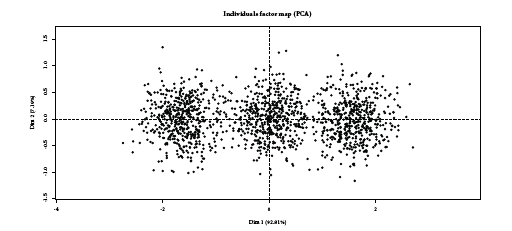
The goal of PCA [3] is to represent observations graphically in a way that exhibits most efficiently their similitude and differences by combining input features in so-called orthogonal “principal components” u = (u1, …, ud) such that the inertia of each axis j (the variance of \(\boldsymbol{x}' \boldsymbol{u}_j\)) is maximized. It can be shown that it is equivalent to seeking the ordering of the eigenvalues λ = (λ1, …, λd) of the covariance matrix \(\Sigma = \boldsymbol{\mathbf{x}}'\boldsymbol{\mathbf{x}}\). The explained variance of each axis j is given by \(\frac{\lambda_j}{\sum_{j'=1}^d \lambda_j'}\). Classically, only the two first axes (u1, u2) (after reordering from largest to lowest explained variance) are used. The composition of theses axes in the original features \(x_j\) is often represented first, to see if groups of features can be formed which would define the subsequent segments. PCA has been applied to the Automobile dataset from CACF (n = 50,000, d = 25 among which 18 continuous and 7 categorical features which number of levels go from 5 - family status - to 100 - brand of the vehicle and 200,000 missing entries) on Figure [2], where the aforementioned principal components’ composition is displayed on Figure [2] (relying on the FactoMineR R package [4]): interestingly, the first axis is dominated by car and loan characteristics such as the vehicle’s price (“APPORT”, “MCDE”, “CREDAC”), its fiscal and mechanical characteristics (“CVFISC”, “POIDSVH”, “CYLVH”) while the second axis is composed of clients’ characteristics such as their age (“anc_DNAISS”, “anc_DNACJ”), their number of children (“NBENF”), their job stability (“anc_AMEMBC”). Note that a good portion of the total variance is explained by the first axes (22.54 % and 18.97 % resp.). The second classical representation is the observations themselves in this new space, which is displayed on Figure [2]: no clear group is distinguishable from the pack. With these two representations, the Credit Scoring practitioner decide if, visually, clusters are formed (i.e. clouds with little intra-class variance) which would be used to build separate scorecards \((p_{\boldsymbol{\theta}^{1}},p_{\boldsymbol{\theta}^{2}})\).
However, the Credit Scoring data is of mixed type and Credit Scoring practitioners are used to quantizing the data, such that the MCA algorithm, specific to categorical features, becomes applicable to all features, by using e.g. equal-freq or χ2 tests.
In presence of only categorical features (or following quantization), the MCA algorithm is more appropriate: it extends the PCA approach to categorical features by using the disjunctive table (dummy / one-hot encoding of \(\boldsymbol{\mathbf{x}}\)). For a thorough introduction to MCA, see e.g. [5]. What is most interesting in this method is that both categorical features’ levels and observations can be simultaneously displayed on the first principal components axes. This is of high practical interest in Credit Scoring because clouds of points are directly characterized by the categorical levels that are displayed nearest, contrary to PCA where groups correspond to surfaces of equation \(\boldsymbol{x} ' \boldsymbol{u}_1 + \boldsymbol{x} ' \boldsymbol{u}_2 \geq \alpha\) where α encodes the separation boundary of resulting clusters, which would be the edges of our decision system, as on Figure [1], and make it arguably less interpretable.
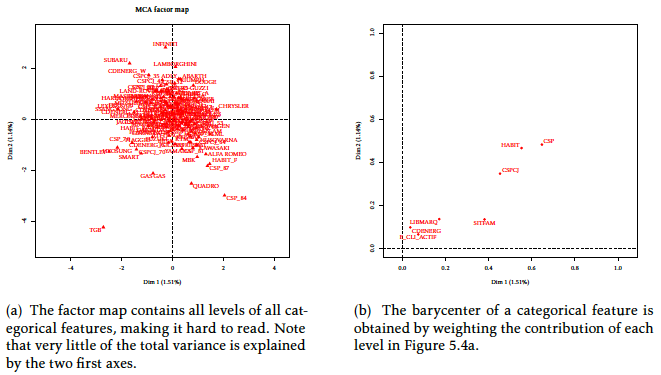
When applied to the Automobile dataset, the MCA algorithm yields Figure [3] (relying again on the FactoMineR R package [4]). As categorical features’ levels are dummy encoded, they are all represented separately as in Figure [3]. Unfortunately, as the vehicle’s brand takes a lot of levels, this figure is not very informative. A useful trick, apart from grouping levels, is to plot the barycentre of a feature’s levels (weighted by the number of observations in each level), as displayed on Figure [3]. Note that a low portion of the total variance is explained by the first axes (1.51 % and 1.14 % resp.) since the data, when one-hot encoded, is very high dimensional. As for PCA, no groups are formed when displaying the (uninformative) equivalent of Figure [2] and no factor level(s) is / are isolated from the others in Figure [3]. A practitioner would conclude the absence of segments on which to build several scorecards.
Nevertheless, a method applicable to mixed data exists as well and could directly be applied to “raw” features.
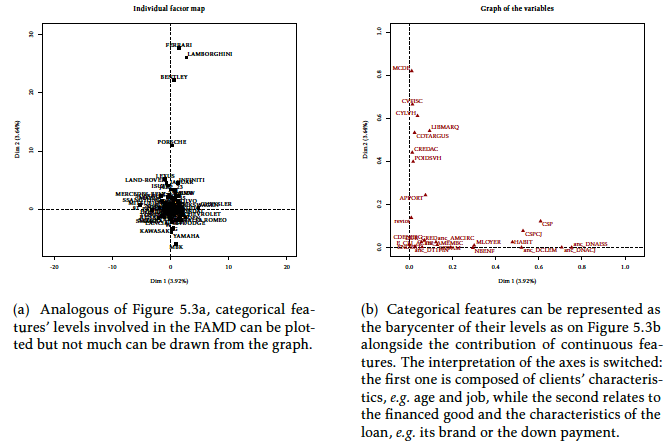
The FAMD algorithm [3] aims at performing both MCA on categorical features and PCA on continuous features in a simultaneous fashion. Resulting principal component axes depend on both data types, as can be seen from Figure [4] (relying again on the FactoMineR R package [4]). As on Figures [2] and [3], categorical features’ levels’ and continuous features’ contributions to the two first principal components can be displayed on Figure [4], where vehicle brands make it rather hard to read. When switching to the categorical features’ levels barycentre representation, as in Figure [3], interpretation is easier and somewhat similar to the PCA method (up to a permutation on the first and second components): the first axis contains information about the client, represented by continuous (e.g. age) and categorical features (e.g. job category) while the second axis is about the loan and the vehicle (its brand, cost, etc.). This method has the advantage of not requiring the Credit Scoring practitioner to preprocess the “raw” data by quantizing it, which could have a huge impact on the results of the subsequent method employed. Moreover, the practitioner would fine-tune the quantization of each sub-population which, if fed back to the MCA, would potentially yield completely different results! As for PCA and MCA, the equivalent of Figure [2] (not shown here) for FAMD does not display distinguishable groups of observations. Nevertheless, the luxury car brands are now well separated in Figure [4] from other continuous features and other categorical features’ levels which would be interpreted by a Credit Scoring practitioner as the need to build a specific scorecard for this market. However, due to the low volumes of applicants and considering that all of them are probably good clients that are all accepted (the score has little relevance for such markets), no segmentation would be performed.
It appears clearly that all these methods do not directly optimize a predictive goal such as the one optimized by logistic regression. Moreover, the ad hoc preprocessing step of quantization might influence the structure of the retained segmentation.
For numerical experiments of Section 1.6, we will use, among others, the FAMD approach.
These practices can fail
Of course, like all ad hoc methods that rely on “two-stages” procedures (find segments using an MCA algorithm and learn separate logistic regression scorecards on them) which do not share a common objective, the aforementioned in-house practice can fail. Credit Scoring practitioners are probably aware that their methods are not bullet-proof, but like most industries, unless provided to them with easily usable software replacing these methods, these practices remain.
This article has no intent in filling that gap but rather to give insights on more elaborate, readily usable methods that will be covered in Section 1.2 and to propose a few ideas for future research. That is why, in the present, we show two data generating mechanisms where current in-house methods fail. In Section 1.3, we will propose an SEM algorithm that shares similitude with the one proposed for quantization that performs well where current methods fail.
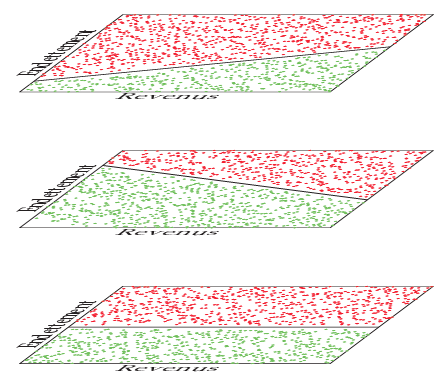
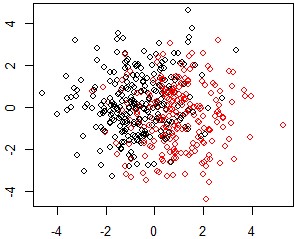
The first of these failing situations is when the pdf of covariates (suppose for simplicity that all of them are continuous) \(p(\boldsymbol{x})\) is multi-modal as on Figure [5] where we distinguish the lower, middle and upper-classes of respective low, average and high wages and indebtedness. An unsupervised generative approach like PCA would urge the practitioner to construct 3 scorecards (one for each of the aforementioned classes). However, displaying y as red (resp. green) for bad borrowers (resp. good borrowers), we can see that perfect separation can be achieved: it depends solely on the indebtedness level (the ratio of wages over indebtedness). Thus, the resulting scorecards would be asymptotically the same, but they use three times more parameters! In a finite sample setting, it will imply lower performance since each of these coefficients have three times less samples to train on, which amounts to increasing the variance by the same factor. On a practical note, one could argue that it reduces interpretability by adding an avoidable complexity to the decision system. This particular data generating mechanism is revisited in the experiments of Section 1.6.1.
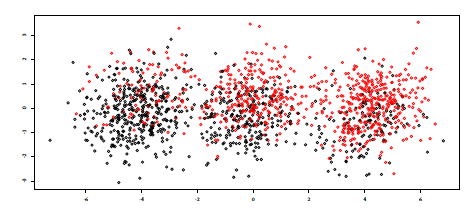
The second failing situation is the counterpart of the first tailored data generating mechanism. This time, suppose the covariates wages and indebtedness are uniformly sampled. Suppose there is a third categorical feature “wages source” which is drawn uniformly from three levels: renters, salaried workers and self-employed. One could argue that renters’ risk level do not depend on their indebtedness, which is typically low (and a higher one is a major red flag), salaried workers’ risk level is positively correlated with their indebtedness ratio as was the case for the first introductory example (see Figure [5]) and self-employed people’s risk level is negatively correlated with this indebtedness ratio (say, the higher their personal engagement, the higher the chances of success of their business). This example data generating mechanism is illustrated on Figure [6]. In this situation, and contrary to the first example, an unsupervised generative “clustering” algorithm like the projection of the data on the two first PCA axes shown here would not partition the data and the Credit Scoring practitioner would construct only one scorecard. This scorecard would have high model bias since it is too simple to accommodate for the variety of the data generating mechanism and consequently perform poorly. This particular data generating mechanism is also revisited in the experiments of Section 1.6.1.

Literature review
This section aims at providing an eluded literature review of some well-known supervised "clustering approaches" that could be transposed to the Credit Scoring industry.
Supervised generative clustering methods
In the preceding section, examples of classical unsupervised “clustering” methods were given: PCA (continuous data), MCA (categorical data) and ultimately FAMD (mixed data), completed with a projection of the data on their respective two first axes. In this section, focus is given to supervised generative methods. Indeed, a fully generative model \(p(\boldsymbol{x},y)\), if sufficiently flexible, could have easily spotted the bottlenecks of the failures of the PCA approach illustrated on Figures [5] and [6].
The PLS [6] algorithm seeks to combine the strengths, in its original proposal, of PCA in explaining the variance of the features \(\boldsymbol{x}\) and regression in predicting y with the resulting principal components. In a classification setting, it is termed PLS-DA where DA stands for discriminant analysis.
The main idea is to construct a first component from the sum of the univariate regressions of \(\boldsymbol{\mathbf{x}}_j\) on \(\boldsymbol{\mathbf{y}}\), then a second component from the sum of the univariate regressions of \(\boldsymbol{\mathbf{x}}_j\) subtracted by the first component on \(\boldsymbol{\mathbf{y}}\), and so on. In a sense, a trade-off between reconstruction quality of \(\boldsymbol{\mathbf{x}}\) and \(\boldsymbol{\mathbf{y}}\) with as few components as possible is achieved.
The PLS algorithm was used in [7] in a classification setting which results in Figure [7] reproduced with permission1. It is striking how classes are better separated when using PLS. However, this does not guarantee that the resulting inferred segments’ logistic regression will yield better predictive performance, considering that a Credit Scoring practitioner would effectively spot two groups in Figure [7] (right) and separate them on the first PLS axis being above or below a threshold of approximately 0.01. When applied to the Automobile dataset, it does not show such spectacular results (see Figure [8]).
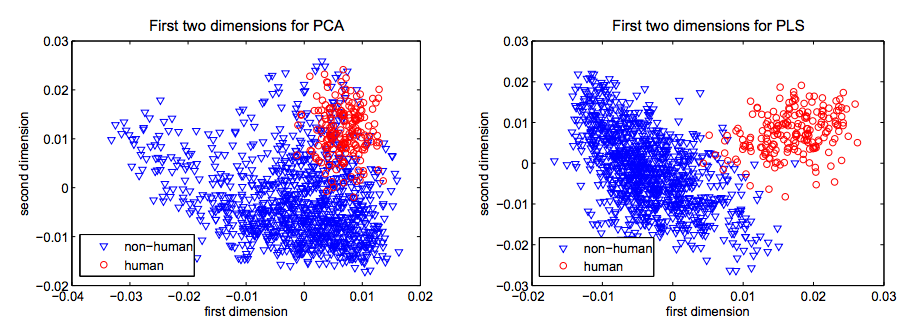
[7]
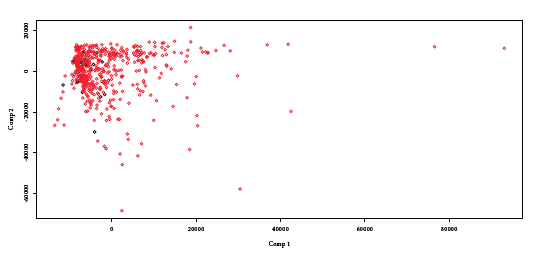
[8]
The SPC [8] algorithm is motivated by genomics applications where d > n, but is applicable to our current setting as well, and by the fact that, in a predictive setting, variance of the features \(\boldsymbol{x}\) is only interesting if correlated with y. The inner-workings of the algorithm are relatively simple: the correlation between each feature \(x_j\) and y is computed. Only the features for which this correlation exceeds a user-defined threshold are retained, and the first few principal components of these features are calculated and used to predict y.
There is a close link between PLS and SPC that is thoroughly explained in [19] Section 18.6.2 p. 680. For numerical experiments of Section 1.6, we will use, among others, the PLS approach.
Although these methods make good use of y in constructing sub-populations on which the practitioner would construct separate scorecards, the resulting segments would be, as described in the MCA Section, visually separated clouds of points on the graph of the two first principal components. This paradigm has two major drawbacks: first, as explained in the preceding section, the separation boundary is complex and multivariate (as the two first principal components will most likely involve all features). Second, to make a complete tree as on Figure [1], these procedures would have to be repeated “recursively” which yields the need for a stopping criterion and an objective splitting criterion in place of the rather subjective visual separation. Direct approaches of estimating such trees are reviewed in the next section.
Direct approaches: logistic regression trees
The first research work focusing on a similar problem than the present one seems to be LOTUS [9], where logistic regression trees are constructed so as to select features to split the data on the tree’s nodes which break the linearity assumption of logistic regression. The original article states an application case similar to this one, namely the insurance market.
Their motivation is that logistic regression has a fixed parameter space, defined by the number of input features, whereas trees adapt their flexibility (i.e. depth) to the sample size n; however, trees perform well for classification (i.e. their label estimates ŷ can achieve low classification error) but poorly in assessing the probability of the event (i.e. the estimate \(\hat{p}(y | \boldsymbol{x})\) is the proportion of the event y among observations \(\boldsymbol{x}\) at each leaf which is arguably not very informative) as it is piecewise constant; if the true decision boundary separating the two classes of y given \(\boldsymbol{x}\) is linear, they need an infinite depth to estimate it as well as logistic regression. Thus, they search for trees which leaves are logistic regression with a few continuous features and which intermediate nodes split the population based on categorical or continuous features which relationship to the log-odd ratio of y is not linear (i.e. features that would perform poorly in a logistic regression).
They propose a feature selection method for node splits that is claimed to be “bias-free”: the number of partitions of \(l_j\) labelled factor levels into mj unlabelled categories (which would here be the tree split criterion and define its sub-populations) is huge which yields overfitting; thus, their approach relies on a χ2 test which degrees of freedom is linked to the number of potential rearrangements of \(l_j\) levels into 2 bins to avoid wrongfully selecting categorical features that have lots of levels. Their optimized criterion is the sum of the log-likelihoods of the logistic regression on the tree’s leaves. Of course, this leads also to overfitting which requires the tree to be pruned (as is classical for classification trees) using a method closely related to the one developed in the classical CART [10] algorithm. Lastly, their proposed method is not directly applicable to missing values: these observations are not used during training (in the Credit Scoring industry, there would most likely be at least one missing value for each observation) and during test, their missing values are imputed by the mean or median.
To sum up, although their motivation is similar to the present problem, LOTUS is not directly usable since only continuous features are used as predictive features in the logistic regression of the tree’s leaves, it does not handle missing values gracefully, and there are currently no implementation available in R or Python.
The second approach very close to our industrial problem is named LMT [11]. As for LOTUS, the result is a tree of logistic regression at its leaves and the motivation is very similar. Their introductory example, reproduced here with permission on Figure [9] is enlightening: a quadratic bivariate boundary cannot be well approximated by trees or logistic regression alone, but a combination of both achieves good performance and interpretation.
Their approach differs however drastically from LOTUS in that they rely on a particular boosting approach derived from the LogitBoost algorithm [12] to adjust the logistic regression, and an adaptation of the classical C4.5 [13] algorithm to grow the tree. The two central ideas behind their usage of the LogitBoost algorithm are simple: it allows to perform feature selection via a stagewise-like process where one feature enters the model at each step and to recursively “refine” the logistic regression by boosting the logistic regression fitted at a node’s parent. Indeed, a first logistic regression is fitted at the tree’s root via LogitBoost using all observations in \(\mathcal{T}_{\text{f}}\), which is further boosted separatly at its subsequent children nodes on sub-populations, say \(((\boldsymbol{\mathbf{x}}^1,\boldsymbol{\mathbf{y}}^1), (\boldsymbol{\mathbf{x}}^2,\boldsymbol{\mathbf{y}}^2))\) and so on. This most probably induces less parameter estimation variance in each leaf since they partly benefit from samples not in their leaf but used to fit the parents’ logistic regression. One if its main advantages compared to other approaches is that it is fast. Here again, the resulting tree must be pruned and either a tactic similar to the classical tree algorithm CART, or cross-validation, or the AIC criterion (in a refinement of the method proposed in [14]) are used.
However, categorical features are dummy / one-hot encoded so that only a few factor levels might be selected at each leaf, which amounts to merging the not selected levels into a reference value. Conversely, when used as a split feature, each level yields a distinct branch. Moreover, missing values are imputed by the mean or mode.
Its original implementation is in Java (Weka) but the R package provides interfaces and wrappers to it. When applied directly to the Automobile dataset, as LMT does not handle missing values, a first preprocessing step is to select only complete observations: there remains only approx. 4,000 observations (among 50,000) and no segmentation is performed. Due to the use of the LogitBoost algorithm, only a few features are selected: one continuous feature and three particular levels of three different categorical features, yielding a rather low performance of 44.3 Gini points (compared to the current performance of 55.7) which is nevertheless impressive given the few training observations and features used. To help the LMT algorithm further, features with the highest rate of missing values are deleted; we now have d = 21 and n = 20, 000. Finally, in a third experiment, missing values of categorical features are encoded as a particular level and continuous features’ missing values are imputed by their mean, all observations and features can now be used. In these two last experiments, the LogitBoost algorithm seems to fail since no segmentation is performed and only the age of the client is retained, yielding a low performance (30 Gini points).
![[fig:lmt1] Quadratic data generation process: the true boundary depends on the square of input features.](figures/chapitre6/lmt_generation.png)
![[fig:lmt2] The first split of a classification tree is way too simplistic.](figures/chapitre6/lmt_tree_1.png)
![[fig:lmt3] The second split is more helpful.](figures/chapitre6/lmt_tree_2.png)
![[fig:lmt4] The subsequent splits yield overfitting: these nodes shall be pruned.](figures/chapitre6/lmt_tree_3.png)
![[fig:lmt5] A lr tree with only two leaves (and consequently two lr) yields the best result.](figures/chapitre6/lmt_logistic.png)
Lastly, a third approach closely related to our problem is MOB [15] which is an adaptation of a better-known paper [16] to parametric models in the leaves of a recursively partitioned dataset (hence the name).
Their algorithm consists in fitting the chosen model (in our case, logistic regression) for all observations in \(\mathcal{T}_{\text{f}}\) at the current node and decide to split these into subsets based on a correlation measure (several such measures are proposed) of the residuals of the current model and splitting features V = (V1, …, Vp) where \(V_j \in \mathbb{R}\) or \(\mathbb{N}_{o_j}\), 1 ≤ j ≤ p, which are not necessarily included in \(\boldsymbol{\mathbf{x}}\) (they are specified by the user). The procedure is repeated until no significant “correlation” is detected. The C4.5 algorithm, in presence of a binary outcome, orders the levels of categorical features by their proportion of events y and split as if the feature were ordinal (it can be shown that it is optimal, see [19] Section 9.2.4). Similarly to LOTUS and contrary to C4.5, MOB performs, for example for binary splits and when confronted to categorical features j having \(l_j\) levels, \(2^{l_j}\) tests. Moreover, there is no mention of an eventual treatment of missing values. Finally, the number of segments per split is searched exhaustively.
Its implementation is available through the R packages and which will be used in numerical experiments of Section 1.6. It worked well on small toy data, however, on real data, even with complete cases (n = 4, 000) and by arbitrarily selecting d = 4 features, computation took a very long time. With bigger datasets, I got “file size”-related errors.
To sum up, these direct approaches are far more promising than unsupervised and supervised generative approaches of Sections 1.1.2 and 1.2.1 respectively, in that they produce directly the sought tree-structure of Figure [1] (apart, of course, from quantization \(\boldsymbol{q}^1, \dots, \boldsymbol{q}^7\) and interactions \(\boldsymbol{\delta}^1, \dots, \boldsymbol{\delta}^7\)). However, their treatment of missing values and categorical features are not satisfactory: classical Credit Scoring data would require preprocessing steps such as imputation or quantization (or at least merging numerous factor levels) which might greatly influence the resulting segmentation as emphasized in Section 1.1.1. Moreover, quantization has to be segment-specific: on a theoretical note, it participates in reducing model bias; on a practical note, it does not make much sense to use the same quantization of wages on segments of applicants to a leasing for a Ferrari or for a smartphone.
In the next section, we formalize the problem as a model selection problem, similarly to the three approaches presented here, with our own notations introduced in the previous section.
Logistic regression trees as a combinatorial model selection problem
We assume there are \(\text{K}^\star\) “clusters” which form the leaves of a tree similar to Figure [1] and which assigning latent random feature is denoted by \(\text{C}^\star\) (lower-case for observations). The other notations employed inspire from the preceding posts: the superscript notation is used to insist on the fact that available features \(\boldsymbol{x}^{c^\star}\) differ potentially in each of the scorecards. For \(c^\star \in \mathbb{N}_{\text{K}^\star}\), \((\boldsymbol{\mathbf{x}}^{c^\star}, \boldsymbol{\mathbf{y}}^{c^\star})\) denotes the subset of observations of \((\boldsymbol{\mathbf{x}}_{\text{f}}, \boldsymbol{\mathbf{y}}_{\text{f}})\) for which \(\text{C}^\star = c^\star\), such that \(\cup_{c^\star=1}^{\text{K}^\star} (\boldsymbol{\mathbf{x}}^{c^\star}, \boldsymbol{\mathbf{y}}^{c^\star}) = (\boldsymbol{\mathbf{x}}_{\text{f}}, \boldsymbol{\mathbf{y}}_{\text{f}})\) and for c⋆, c′⋆, \((\boldsymbol{\mathbf{x}}^{c^\star}, \boldsymbol{\mathbf{y}}^{c^\star}) \cap (\boldsymbol{\mathbf{x}}^{c^{'\star}}, \boldsymbol{\mathbf{y}}^{c^{'\star}}) = \varnothing\). It follows that quantizations \(\boldsymbol{q}^{c^\star}\) and interactions \(\boldsymbol{\delta}^{c^\star}\), discussed in earlier posts are also different. Consequently, the logistic regression coefficients \(\boldsymbol{\theta}^{\star,c^\star}\) are also obviously different. In this section, we drop the quantization and interactions requirement, such that:
$$\label{eq:lr_tree}
\forall \boldsymbol{x}, y, \exists c^\star \in \mathbb{N}_{\text{K}^\star}, \boldsymbol{\theta}^{\star,c^\star} \in \Theta^{\star,c^\star}, p(y | \boldsymbol{x}) = p_{\boldsymbol{\theta}^{\star,c^\star}}(y | \boldsymbol{x}).$$
The membership of an observation \(\boldsymbol{x}\) to a segment \(\text{c}\) is given by a tree. We restrict to binary trees for simplicity, such that a segment \(\text{c}\) with depth 𝒟(c) has r = 1, …, 𝒟(c) parents successively denoted by 𝒫ar(c). At these parent nodes, a binary rule is taken. This rule is univariate: it depends on only one feature \(x_{\sigma(r,c)}\) where σ(r, c) denotes the anti-rank of the feature used in rule r for segment \(\text{c}\). Being a binary rule, the membership of \(x_{\sigma(r,c)}\) is tested between C𝒫ar(c), 1 and C𝒫ar(c), 2 such that \(C_{\mathcal{P}a^r(c),1} \cup C_{\mathcal{P}a^r(c),2} =\mathbb{R}\) for continuous features (half-spaces), or \(\mathbb{N}_{l_{\sigma(r,c)}}\) for categorical features respectively. This membership is denoted by λ(r, c) such that \(x_{\sigma(r,c)} \in C_{\mathcal{P}a^r(c),\lambda(r,c)}\). With all these newly introduced notations, the probability of a segment \(\text{c}\) given covariates \(\boldsymbol{x}\) can be expressed as:
$$\label{eq:tree}
p( c | \boldsymbol{x}) = \prod_{r = 1}^{\mathcal{D}(c)} {1}_{C_{\mathcal{P}a^r(c),\lambda(r,c)}} (x_{\sigma(r,c)}).$$
An example is given on Figure [10].
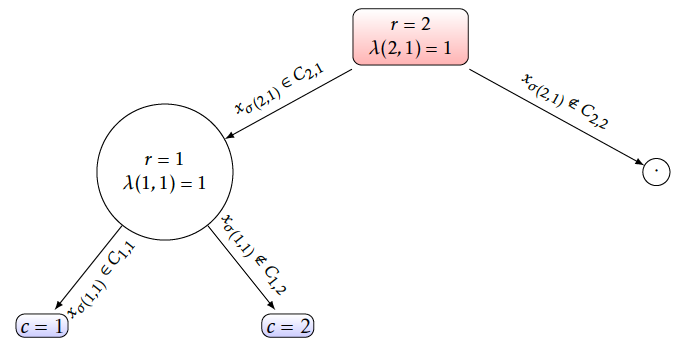 [10]
[10]
The above mentioned algorithms LOTUS, LMT and MOB optimized the sum of the segments’ log-likelihoods, then needed pruning since it leads to obvious overfitting: infinite log-likelihood is achievable by putting each sample into its own segment, provided there is at least one continuous feature and no identical examples with different labels, or combinations of categorical features’ levels that separate classes perfectly.
Another approach can be taken by considering the segment \(\text{c}\) as a latent random feature:
$$\begin{aligned}
p(\boldsymbol{\mathbf{x}}_{\text{f}},\boldsymbol{\mathbf{y}}_{\text{f}}) & = \sum_{c=1}^{\text{K}^\star} p(\boldsymbol{\mathbf{y}}_{\text{f}} | \boldsymbol{\mathbf{x}}_{\text{f}}, c) p(c | \boldsymbol{\mathbf{x}}_{\text{f}}) p(\boldsymbol{\mathbf{x}}_{\text{f}}) & \text{($p(c | \boldsymbol{x})$ is non-zero only for $c = c^\star$)} \nonumber \\
& = \prod_{c^\star=1}^{\text{K}^\star} p(\boldsymbol{\mathbf{y}}^{c^\star} | \boldsymbol{\mathbf{x}}^{c^\star}, c^\star) p(\boldsymbol{\mathbf{x}}_{\text{f}}) \nonumber \\
& = \prod_{c^\star=1}^{\text{K}^\star} \int_{\Theta^{\star,c^\star}} p_{\boldsymbol{\theta}^{\star, c^\star}}(\boldsymbol{\mathbf{y}}^{c^\star} | \boldsymbol{\mathbf{x}}^{c^\star}) p(\boldsymbol{\theta}^{\star, c^\star} | c^\star) d\boldsymbol{\theta}^{\star, c^\star} p(\boldsymbol{\mathbf{x}}_{\text{f}}).
\end{aligned}$$
Thus, we have:
$$\begin{aligned}
\ln p(\boldsymbol{\mathbf{x}}_{\text{f}},\boldsymbol{\mathbf{y}}_{\text{f}}) & = \sum_{c^\star = 1}^{K^\star} \int_{\Theta^{\star,c^\star}} \ln p_{\boldsymbol{\theta}^{\star, c^\star}}(\boldsymbol{\mathbf{y}}^{c^\star} | \boldsymbol{\mathbf{x}}^{c^\star}) p(\boldsymbol{\theta}^{\star, c^\star} | c^\star) d\boldsymbol{\theta}^{\star, c^\star} + \ln p(\boldsymbol{\mathbf{x}}_{\text{f}}) \\
& \approx - \sum_{c^\star=1}^{K^\star} \text{BIC}(\theta^{\star,c^\star})/2 + O(K^\star) + \ln p(\boldsymbol{\mathbf{x}}_{\text{f}}).\end{aligned}$$
Since in our application, the number of sample n ≈ 106 is large and the number of desired segments K⋆ ≈ 10 is low, we use the following criterion to select a segmentation:
$$\label{eq:BICc}
(\text{K}^\star, c^\star) = \arg\!\min_{\text{K},c} \sum_{c=1}^{\text{K}} \text{BIC}(\hat{\boldsymbol{\theta}}^c).$$
As was thoroughly explained for quantizations and interactions in earlier posts, it is unclear how many parameters should be accounted for in this BIC criterion since the tree (see Equation of \(p(c | \boldsymbol{x})\) above) has “parameters”, in the sense that it selects a splitting feature and a splitting criterion, which have to be estimated (this is somewhat reflected in the Equation of \(\ln p(\boldsymbol{\mathbf{x}}_{\text{f}},\boldsymbol{\mathbf{y}}_{\text{f}})\) above by the \(p(\boldsymbol{\theta}^c | c)\) term); some are continuous (when the split is done on a continuous feature), some are discrete (when it concerns a categorical feature). As discussed in Section [par:consistency], discrete parameters are usually not counted, but here, following the C4.5 approach of considering the levels of categorical features as ordered (w.r.t. the proportion of events y associated to them - see Section 1.2.1), a split on categorical features can count as one continuous parameter. However, when there are more than two classes \(\text{c}\) (typically, a financial institution of moderate to big size would have \(\text{K} = 4\) to 30 scorecards), this “ordering” simplification about the search for discrete parameters does not apply. We still stick with the BIC criterion above as it will show good empirical properties in Section 1.6.
In the next section, we propose to relax the constraint of the tree structure, exactly as was done for quantizations in earlier posts, by using a continuous approximation of this discrete problem (and thus highly difficult to optimize directly).
A mixture and latent feature-based relaxation
The difficulty in optimizing the sum of the BIC criteria directly lies in the discrete nature of \(\text{c}\) given \(\boldsymbol{x}\), illustrated by the profusion of indicator functions in the Equation of the tree, which is very similar to the problems of quantization and interaction screening. In both cases, highly-combinatorial discrete problems were relaxed, by approaching door functions by softmax and relying on MCMC methods. A somewhat similar approach can be taken here to design a “smooth” approximation of \(p(c | \boldsymbol{x})\) which will be denoted by \(p_{\boldsymbol{\beta}}(c | \boldsymbol{x})\): the classical probability estimate of decision trees consisting in the proportion of training examples in each class in all leaves.
The proposed relaxation: tree structure and piecewise constant membership probability
As emphasized in Section 1.2.1, classification trees aim at predicting \(\text{c}\) by making their leaves as “pure” as possible (hence the use of the term “impurity measure” to designate their optimized criterion), i.e. where one class strongly dominates the others by being the labels of most observations that fall into it. However, as for logistic regression, they can be viewed as probabilistic classifiers by substituting their classical majority vote by the proportion of each class in each leaf:
$$\label{eq:tree_leaf}
p_{\boldsymbol{\beta}}(c | \boldsymbol{x}) = \frac{|\mathbf{c}^{\mathcal{L}(\boldsymbol{x}_{\text{f}})}|}{|\boldsymbol{\mathbf{x}}^{\mathcal{L}(\boldsymbol{x})}|},
%p_{\boldsymbol{\beta}}(c | \boldsymbol{x}) = p(c | \mathcal{L}(\boldsymbol{x})),$$
where \(\mathcal{L}(\boldsymbol{x})\) denotes the leaf where \(\boldsymbol{x}\) falls, \(|\mathbf{c}^{\mathcal{L}(\boldsymbol{x})}|\) the number of training examples in \(\boldsymbol{\mathbf{x}}\) of class c, the number of training examples in \(\boldsymbol{\mathbf{x}}\) falling in leaf \(\mathcal{L}(\boldsymbol{x}_{\text{f}})\), and β is sloppily used to denote all parameters involved in classical classification tree methods such as CART and C4.5. Indeed, in this soft assignment, \(\mathcal{L}(\boldsymbol{x})\) and its segment \(\text{c}\) are not identifiable anymore. An example of such behaviour is given on Figure [11] where there are two classes: “survived” and “not survived” for Titanic passengers given their age, sex and passenger class. The proportion of each class in each leaf is given in parentheses.
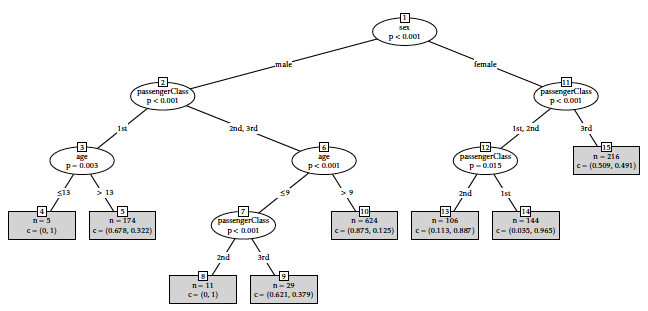 [11]
[11]
This “soft” assignment will be useful to design an algorithm that does not greedily evaluate all possible segmentations of the form of a tree and its subsequent logistic regressions. A softmax could have been used, but would have yielded a major drawback: the assignment decisions would have been multivariate, thus losing the interpretability of the tree structure. Using this new parametrization, we get a mixture model:
$$\begin{aligned}
p(y | \boldsymbol{x}) & = \sum_{c = 1}^{\text{K}} p_{\boldsymbol{\theta}^c}(y | \boldsymbol{x}, c) p_{\boldsymbol{\beta}}(c | \boldsymbol{x}),\end{aligned}$$
where feature \(\text{c}\) is latent and which makes immediately think of a straightforward estimation strategy: the EM algorithm. Indeed, it can be easily remarked that:
$$\begin{aligned}
p(c | \boldsymbol{x}, y) & \propto p_{\boldsymbol{\theta}^c}(y | \boldsymbol{x}, c) p_{\boldsymbol{\beta}}(c | \boldsymbol{x}),\end{aligned}$$
which will be at the basis of the EM’s fuzzy assignment among segments, detailed in the next section.
A classical EM estimation strategy
Following the preceding section, we would like to maximize the following likelihood, both in terms of the segments and their resulting logistic regressions:
$$\ell(\boldsymbol{\beta},\text{K},(\boldsymbol{\theta}^c)_1^{\text{K}} ; \boldsymbol{\mathbf{x}}_{\text{f}}, \boldsymbol{\mathbf{y}}_{\text{f}}) = \sum_{c=1}^{\text{K}} \sum_{i=1}^n \ln p_{\boldsymbol{\theta}^c}(y_i | \boldsymbol{x}_i, c) p_{\boldsymbol{\beta}}(c | \boldsymbol{x}_i).$$
The EM algorithm [20] is an iterative method that can be used to estimate the maximum a posteriori of \(p(c | \boldsymbol{x}, y)\), since \(\text{c}\) is latent, and alternates between the expectation (E-)step, which computes the relative membership of the observations into each segment, and a maximization (M-)step, which computes the mle of the parameters of the log-likelihoods of each segment’s logistic regression and the tree structure. These new logistic regression and tree estimates are then used to determine the distribution of the latent variables in the next E-step. Considering the number of segments \(\text{K}\) fixed, the E- and M-steps of the EM can be derived as follows.
E-step
At iteration (s + 1), the membership of an observation i to segment \(\text{c}\) can be computed as:
$$t_{i,c}^{(s+1)} = \frac{p_{\boldsymbol{\theta}^{c(s)}}(y_i | \boldsymbol{x}_i) p_{\boldsymbol{\beta}^{(s)}}(c | \boldsymbol{x}_i) }{ \sum_{c'=1}^{\text{K}} p_{\boldsymbol{\theta}^{c{'}{(s)}}}(y_i | \boldsymbol{x}_i) p_{\boldsymbol{\beta}^{(s)}}(c{'} | \boldsymbol{x}_i) }.$$
For notational convenience, we denote the matrix of partial membership of all observations to all segments as \(\mathbf{t} = (t_{i,c})_{1\leq i \leq n, 1 \leq c \leq \text{K}}\).
M1-step
The previous E-step allows to derive the new mle of the logistic regression parameters of each segment \(\text{c}\) as:
$$\begin{aligned}
\boldsymbol{\theta}^{c(s+1)} & = \arg\!\max_{\boldsymbol{\theta}^c} \mathbb{E}[\ell(\boldsymbol{\beta}, \text{K}, (\boldsymbol{\theta}^{c{'}})_1^{\text{K}}; \boldsymbol{\mathbf{x}}_{\text{f}}, \boldsymbol{\mathbf{y}}_{\text{f}}, \mathbf{t}^{(s+1)}) | (\boldsymbol{\theta}^{(c(s)})_1^{\text{K}}, \boldsymbol{\beta}^{(s)}, \text{K}] \\
& = \arg\!\max_{\boldsymbol{\theta}} \sum_{i=1}^n t_{i,c}^{(s+1)} \ln p_{\boldsymbol{\theta}^c}(y_i | \boldsymbol{x}_i).\end{aligned}$$
M2-step
Similarly, a new tree structure can be derived by the new mle of its parameter \(\boldsymbol{\beta}\):
$$\begin{aligned}
\boldsymbol{\beta}^{(s+1)} & = \arg\!\max_{\boldsymbol{\beta}} \mathbb{E}[\ell(\boldsymbol{\beta}, \text{K}, (\boldsymbol{\theta}^c)_1^{\text{K}}; \boldsymbol{\mathbf{x}}_{\text{f}}, \boldsymbol{\mathbf{y}}_{\text{f}}, \mathbf{t}^{(s+1)}) | \boldsymbol{\theta}^{(c(s)}, \boldsymbol{\beta}^{(s)}, \text{K}] \\
& = \arg\!\max_{\boldsymbol{\beta}} \sum_{i=1}^n \sum_{c=1}^{\text{K}} t_{i,c}^{(s+1)} \ln p_{\boldsymbol{\beta}}( c | \boldsymbol{x}_i),\end{aligned}$$
where \(p_{\boldsymbol{\beta}}( c | \boldsymbol{x}_i)\) is estimated by relative frequency in each leaf, such that \(p_{\boldsymbol{\beta}}(c | \boldsymbol{x}) = \frac{|\mathbf{c}^{\mathcal{L}(\boldsymbol{x})}|}{|\boldsymbol{\mathbf{x}}^{\mathcal{L}(\boldsymbol{x})}|}\). Unfortunately, tree induction methods like CART or C4.5 do not follow a maximum likelihood approach, so that they rather try to minimize a so-called impurity measure, the Gini index or the entropy, respectively. However, since it is hoped that segments c⋆ are “peaks” of the distribution \(p_{\boldsymbol{\beta}}( c | \boldsymbol{x})\), just as it was supposed that the best quantization \(\boldsymbol{\mathfrak{\boldsymbol{q}}}^\star\) dominated its posterior pdf in the SEM algorithm, we assume the log-likelihood can be approximated by the entropy:
$$\boldsymbol{\beta}^{(s+1)} \approx \arg\!\max_{\boldsymbol{\beta}} \sum_{i=1}^n \sum_{c=1}^{\text{K}} t_{i,c}^{(s+1)} \underbrace{p_{\boldsymbol{\beta}}( c | \boldsymbol{x}_i)}_{\begin{cases} \approx 1 \text{ for } c = c^\star, \\ 0 \text{ otherwise.} \end{cases}} \ln p_{\boldsymbol{\beta}}( c | \boldsymbol{x}_i).$$
This last formulation allows to obtain \(\boldsymbol{\beta}^{(s)}\) from a simple application of the C4.5 algorithm, with observations properly weighted by ti, c.
However, this approach suffers from two main drawbacks: first, all observations are used in all logistic regression \(p_{\boldsymbol{\theta}^c}\) which might be problematic with real data since there will be “blocks” of available features (e.g. vehicle information); second, all possible values of \(\text{K}\) must be iterated through since the EM algorithm does not allow for the disappearance of a segment \(\text{c}\) contrary to the SEM approach developed hereafter.
An SEM estimation strategy
In a similar fashion as the MCMC approaches developed in earlier posts where a “clever” quantization (resp. interaction matrix) was drawn and evaluated at each step, refining it for the subsequent steps, a straightforward way of building logistic regression trees is to propose a tree structure, fit logistic regression at its leaves, and evaluate the goodness-of-fit using the sum of the BIC criteria of the resulting logistic regressions. This is somehow the way LMT works: a tree structure is proposed based on C4.5, logistic regression are fitted using the LogitBoost algorithm, and the tree is pruned back using a goodness-of-fit criterion.
Similarly to the quantization and the interaction screening problems, doing so for all possible tree structures is intractable, so that a way of generating “good” candidates can be designed by relying on an SEM algorithm, which we call glmtree. The E-step of the previous section is thus replaced by a Stochastic (S-) step which has some consequences on the M-steps.
S-step
The “soft” assignment of the EM algorithm of the previous section is hereby replaced by a “hard” stochastic assignment such that:
$$c_i^{(s+1)} \sim p_{\boldsymbol{\theta}^{\cdot(s)}}(y_i | \boldsymbol{x}_i) p_{\boldsymbol{\beta}^{(s)}}(\cdot | \boldsymbol{x}_i).$$
M1-step
Thanks to the previous step, the segments are now “hardly” assigned such that the logistic regression are estimated using only observations affected to their segment:
$$\begin{aligned}
\boldsymbol{\theta}^{c(s+1)} & = \arg\!\max_{\boldsymbol{\theta}^c} \ell(\boldsymbol{\theta};\boldsymbol{\mathbf{x}}^{c(s+1)},\boldsymbol{\mathbf{y}}^{c(s+1)}) \\
& = \arg\!\max_{\boldsymbol{\theta}^c} \sum_{i=1}^n {1}_{c}(c_i^{s+1)}) \ln p_{\boldsymbol{\theta}^c}(y_i | \boldsymbol{x}_i, c).\end{aligned}$$
M2-step
Similarly, a new tree structure is given by:
$$\begin{aligned}
\boldsymbol{\beta}^{(s)} & = \arg\!\max_{\boldsymbol{\beta}} \ln p_{\boldsymbol{\beta}}(c_i | \boldsymbol{x}_i) \\
& = \arg\!\max_{\boldsymbol{\beta}} \ell(\boldsymbol{\beta}; \boldsymbol{\mathbf{x}}, \mathbf{\boldsymbol{c}}).\end{aligned}$$
This last expression is again approximated by C4.5’s impurity measure: the entropy. Without more theoretical and empirical work, it is unclear which of the EM and SEM approaches will perform best. However, as mentioned earlier, this SEM algorithm calls for an easy integration with the quantization and interaction screening methods proposed in earlier posts.
Choosing an appropriate number of “hard” segments
Going back to “hard” segments
The motivation of Section 1.4.1 was to propose a relaxation of the tree structure so that an iterative estimation, be it an EM or an SEM algorithm, could be carried out. In an earlier post, a similar relaxation was proposed for quantization, which lead us to propose a “soft” quantization \(\boldsymbol{q}_{\boldsymbol{\alpha}}(\cdot)\) or \(p_{\boldsymbol{\alpha}}(\boldsymbol{\mathfrak{\boldsymbol{q}}}_j | \cdot)\) for the neural network and the SEM approaches respectively. These relaxations allowed quantized features to be “partly” in all intervals or groups for continuous or categorical features respectively. Thus, to get back to the original quantization problem, a maximum a posteriori scheme was introduced in an earlier post to deduce “hard” quantizations from this relaxation. In our tree setting, a similar approach has to be taken: this soft segmentation can be interpreted as a mixture of logistic regression which implies that all applicants are scored by all scorecards which is arguably not interpretable. An assignment of each applicant i to a single scorecard, i.e. to a leaf of the segmentation tree, is easily done again by a maximum a posteriori step such that:
$$\label{eq:max_seg}
\hat{c}_i^{(s)} = \arg\!\max_c p_{\boldsymbol{\beta}^{(s)}}(c | \boldsymbol{x}_i).$$
Segmentation candidates
Similarly to the neural network architecture introduced in San earlier post, the SEM algorithm which proposed quantization candidates and the Metropolis-Hastings algorithm for pairwise interaction screening, both introduced in earlier posts, the EM and SEM strategies introduced in the two previous sections for segmentation are merely “segments providers”. Indeed, through the iterations 1 to S, as argued in the preceding paragraph, segmentations \(\hat{\mathbf{c}}^{(1)}, \dots \hat{\mathbf{c}}^{(S)}\) are proposed through a maximum a posteriori rule parallel to these algorithms. These candidates are then reintroduced to our original criterion (sum of BIC criteria) and the best performing segmentation is found according to:
$$\label{eq:BICtree}
s^\star = \arg\!\min_s \text{BIC}(\hat{\boldsymbol{\theta}}^{c^{(s)}}).$$
Exploring a fewer number of segments
In the preceding sections, the number of segments \(\text{K}\) was assumed to be fixed. However, the maximum a posteriori scheme introduced in this section allows, similarly to the one used to go from “soft” (\(\boldsymbol{q}_{\boldsymbol{\alpha}}(\cdot)\) or \(p_{\boldsymbol{\alpha}}(\boldsymbol{\mathfrak{\boldsymbol{q}}}_j | \cdot)\)) to “hard” (\(\boldsymbol{q}(\cdot)\)) quantizations, to explore a number of segments potentially way lower than \(\text{K}\): for a fixed segment \(\text{c}\), if there is no observation i such that \(p_{\boldsymbol{\beta}}(c | \boldsymbol{x}_i)\) > \(p_{\boldsymbol{\beta}}(c' | \boldsymbol{x}_i)\) for c′ ≠ c, than the segment is empty, which is equivalent to producing a segmentation in \(\text{K}-1\) segments. Supplemental to this thresholding effect, the use of an SEM algorithm makes it possible to enforce this phenomenon: as \(\text{c}\) is drawn in the S-step, and as was argued for quantizations with an SEM algorithm, there is a non-zero probability of not drawing a particular segment \(\text{c}\) at a given step (s). When run long enough, the chain will stop with \(\text{K} = 1\), just like the glmdisc-SEM algorithm could be run until all features are quantized in one level. This can be seen as a strength since it does not require to loop on the number of segments \(\text{K}\) which would be required for an EM algorithm, which is why focus is given to the SEM algorithm in what follows.
Extension to quantization and interactions
The SEM estimation strategy proposed in the previous section has one clear advantage: it could easily be used in conjunction with the glmdisc-SEM algorithm proposed in earlier posts for quantization and interaction screening. Following the preceding sections, we would like to maximize the following likelihood, both in terms of segments, the quantizations in each segment and the resulting logistic regressions:
$$\ell((\boldsymbol{\alpha}^c)_1^{\text{K}}, \boldsymbol{\beta},\text{K},(\boldsymbol{\theta}^c)_1^{\text{K}} ; \boldsymbol{\mathbf{x}}_{\text{f}}, \boldsymbol{\mathbf{y}}_{\text{f}}) = \sum_{c=1}^{\text{K}} \sum_{i=1}^n \ln p_{\boldsymbol{\theta}^c}(y_i | \boldsymbol{\mathfrak{\boldsymbol{q}}}_i, c) p_{\boldsymbol{\beta}}(c | \boldsymbol{x}_i) p_{\boldsymbol{\alpha}^c}(\boldsymbol{\mathfrak{\boldsymbol{q}}}_i | \boldsymbol{x}_i).$$
The following modifications to the two SEM algorithms (for the quantization and segmentation problems) previously proposed would have to be performed:
S1-step
The segment is drawn, for an observation i such that \(\boldsymbol{x}_i\) belongs to segment \(\text{c}\), according to:
$$c_i^{(s+1)} \sim p_{\boldsymbol{\theta}^{\cdot(s)}}(y_i | \boldsymbol{\mathfrak{\boldsymbol{q}}}^{\cdot(s)},\boldsymbol{\delta}^{\cdot(s)}) p_{\boldsymbol{\beta}^{(s)}}(\cdot | \boldsymbol{x}_i).$$
S2-step
The glmdisc-SEM performs the subsequent S-steps. The quantization is drawn according to:
$$\boldsymbol{\mathfrak{\boldsymbol{q}}}_{i,j}^{c(s+1)} \sim p_{}(y_i | \boldsymbol{\mathfrak{\boldsymbol{q}}}_{i,-\{j\}}, \cdot, \boldsymbol{\delta}^{c(s)}) p_{\boldsymbol{\alpha}_j^{c(s)}}(\cdot | x_{i,j}).$$
S3-step
The interaction matrix is drawn following the Metropolis-Hastings approach developed in earlier posts and denoted for simplicity as MH here:
$$\boldsymbol{\delta}^{c(s+1)} \sim \text{MH}(\boldsymbol{\delta}^{c(s)}, \boldsymbol{\mathbf{q}}^{c(s+1)}, \boldsymbol{\mathbf{y}}^{c(s+1)}).$$
M1-step
The logistic regression parameters are obtained in each segment by using the appropriate quantization, interaction matrix and observations:
$$\boldsymbol{\theta}^{c(s+1)} = \arg\!\max_{\boldsymbol{\theta}} \ell(\boldsymbol{\theta};\boldsymbol{\mathbf{x}}^{c(s+1)},\boldsymbol{\mathbf{y}}^{c(s+1)}, \boldsymbol{\delta}^{c(s+1)}).$$
M2-step
In each segment and for each predictive feature in this particular segment, polytomous logistic links are fitted between the “soft” quantization and the raw feature:
$$\boldsymbol{\alpha}_j^{c(s+1)} = \arg\!\max_{\boldsymbol{\alpha}_j} \ell(\boldsymbol{\alpha}_j;\boldsymbol{\mathbf{x}}_j^{c(s+1)},\boldsymbol{\mathbf{q}}_j^{c(s+1)}).$$
M3-step
The tree-structure is obtained again via the C4.5 algorithm as an approximation of:
$$\boldsymbol{\beta}^{(s+1)} = \arg\!\max_{\boldsymbol{\beta}} \ell(\boldsymbol{\beta}, \boldsymbol{\mathbf{x}}, \mathbf{\boldsymbol{c}}^{(s+1)}).$$
Parallel to this SEM algorithm, “hard” quantizations are obtained by performing a maximum a posteriori operation on the quantization probability \(p_{\boldsymbol{\alpha}}\):
$$\hat{q}_{j,h}^{c(s)}(\cdot) = 1 \text{ if } h = \arg\!\max_{1 \leq h' \leq m_j} p_{{\boldsymbol{\alpha}}_{j,h'}^{(c(s)}}(\boldsymbol{e}_{h'}^{m_j} | \cdot), 0 \text{ otherwise.}$$
As proposed in Section 1.4.4, “hard” segments are obtained via a maximum a posteriori operation on the segmentation probability \(p_{\boldsymbol{\beta}}\). The best logistic regression tree is thereafter chosen via the sum of the BIC criteria.
Although this extension seems straightforward, it is relatively computationally expensive since at each step (s), \(\text{K}\) Metropolis-Hastings steps have to be performed and a tree, \(\text{K}\) logistic regression and \(\text{K} \times d\) polytomous logistic regressions are fitted. With a relatively small number of segments, i.e. 4 to 30 as proposed earlier, it seems nevertheless feasible but it will require more work. In particular, since classification tree methods with more than 2 labels are computationally intensive when presented with categorical features with many levels (see Section 1.2.2), a straightforward workaround is to consider the quantized features as ordered.
Numerical experiments
This post is based on more recent work which consequently limits the exhaustiveness of the numerical experiments. The next section aims at comparing the proposed approach to other methods on simulated data from the proposed model, and in particular the failing situations discussed in Section 1.1.3.
Empirical consistency on simulated data
The first set of numerical experiments are dedicated to verifying empirically the consistency of the proposed approach. To do so, we simulate the failing situations presented in Section 1.1.3.
Two covariates \((x_1,x_2)\) are independently simulated from an equally probable mixture of 𝒩(3, 1), 𝒩(6, 1) and 𝒩(9, 1) and the log odd ratio of y is given by \(\theta_0 + \theta_1 x_1 + \theta_2 x_2\) where θ0 = 3, θ1 = 0.5 and θ2 = − 1. This data generating mechanism is illustrated in Figure [12]. Results of various clustering methods developed in this post are given in Table [1].
Two covariates \((x_1,x_2)\) are simulated from 𝒰(0, 1) and a third categorical covariate \(x_3\) with 6 uniformly drawn levels. For levels 1 and 2 of feature \(x_3\), the log odd ratio of y is given by \(\theta_1 x_1 + \theta_2 x_2\) where θ1 = − 1 and θ2 = 0.5. For levels 3 and 4, we have θ1 = − 0.5 and θ2 = 1.5 and finally for levels 5 and 6, we set θ1 = 1 and θ2 = − 0.5. This data generating mechanism is illustrated in Figure [13]. Results of various clustering methods developed in this post are given in Table [2].
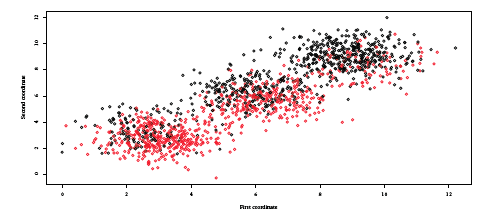
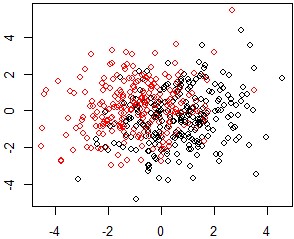
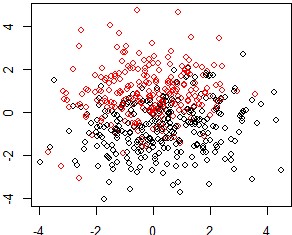
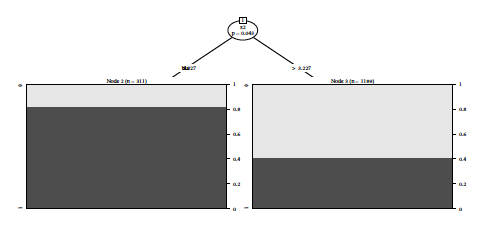
For both experiments, the SEM algorithm is initialized randomly with \(\text{K} = 5\) segments. In experiment (a), the proposed approach selects effectively no partitions. The maximum a posteriori scheme is able, to make segments “vanish” and explore segmentations with less than \(\text{K}\) segments. In experiment (b), the proposed approach is able to recover the tree structure. Consequently, the proposed algorithm yields the best performance in both settings. As for FAMD and PLS which resulting projections for experiment (a) are displayed on Figure [14] and [15] respectively, they form 3 clusters and consequently the 3 resulting logistic regression suffer from a higher estimation variance loosely reflected in their inferior performance in Table [1]. LMT recovers the truth by producing a single logistic regression but not MOB (see Figure [17a]) which splits the data into 2 segments. On experiment (b), FAMD produces worse results than a single logistic regression and the benefit of using the target y is clear from the result of PLS (see Table [2]). MOB also recovers the true structure (see Figure [17b]) but not LMT which first splitting node is a continuous feature not involved in the data generating mechanism of the segments as displayed on Figure [16]. For both experiments, it would be useful to report confidence intervals and or bar plots to derive an empirical consistency of the proposed approach.

| Oracle = ALLR | glmtree-SEM | FAMD | PLS | LMT | MOB | |
|---|---|---|---|---|---|---|
| Gini | 69.7 | 69.7 | 65.3 | 47.0 | 69.7 | 64.8 |
| Oracle | ALLR | glmtree-SEM | FAMD | PLS | LMT | MOB | |
|---|---|---|---|---|---|---|---|
| Gini | 69.7 | 25.8 | 69.7 | 17.7 | 48.4 | 65.8 | 69.7 |
Benchmark on Credit Scoring data
The running example: the Automobile dataset
Recall from Sections 1.1.2 and 1.2.1 that PCA, MCA, FAMD and PLS revealed no segments on this dataset and from Section 1.2.2 that LMT produced disappointing results and MOB could not be tested. A logistic regression learnt on 70 % of the sample yields an overall performance of 57.9 Gini points.
By applying glmtree-SEM to the Automobile dataset, we get \(\hat{\text{K}} = 2\) segments defined by the value of the car being over 10, 000 Euros, yielding an overall performance of 58.7 Gini points. This difference might not seem significant, but in the Credit Scoring industry, such small improvements might result in the selection of a few more good applicants (resp. a few less bad applicants) whose car loans are of high amount. It is thus a high stake for financial institutions.
One year of financed applications
A subset of all applications, representative of approx. 30 portfolios with different scorecards, has been extracted for the purpose of the present benchmark with n = 900, 000 observations and d = 18 among which 12 continuous features and 6 categorical features with 6 to 100 levels (most features are similar to the Automobile dataset). The missing values have been preprocessed such that no continuous features have missing values and the categorical features have a separate and meaningful “missing” level. Also for simplification purposes, no quantization or interaction screening is performed so that the SEM algorithm is conducted as presented in Section 1.4.3.
Generative approaches (FAMD and PLS) are not used due to their subjectivity (visual separation) and the fact that they are used by practitioners to provide “local” segments (e.g. for the Automobile market). Hence for such a large dataset, they would have to be applied “recursively” (applying FAMD / PLS on each of the resulting visually separated segments). For computational reasons that became apparent in applying LMT and MOB to the Automobile dataset, these methods cannot cope either with this larger dataset.
Consequently, glmtree-SEM is only compared to the current performance. The combined scorecards have an overall performance of approximately 46 Gini points but they are not on the same “scale” since they were developed at different times. I rely on the Platt scaling method developed in [17] and [18] and used in common machine learning libraries such as Scikit-learn, to put all of them on the same scale by fitting a logistic regression between the observed labels \(\boldsymbol{\mathbf{y}}\) and the scores outputted by each scorecard. After this procedure, overall performance jumps to approximately 54.6 Gini points.
Another possible benchmark with the current segmentation is to learn additive linear logistic regression (hereafter ALLR) for each existing segment. This approach leads to an overall Gini fo 52. As our proposed algorithm glmtree-SEM will be applied without quantization or interaction screening, this result is a “fairer” baseline than the preceding one since they are both in the same model space: additive linear logistic regression trees.
The glmtree-SEM applied to this big dataset yields only \(\hat{\text{K}} = 12\) segments for an overall performance of 50.2 Gini points. This is satisfactory in two aspects: the performance is relatively close to the existing segmentation while using 3 times less segments / logistic regressions. We can hope for even better interpretability and performance by performing quantization and interaction screening. Results are summarized in Table [3].
| Current performance via Platt scaling | glmtree-SEM; K=10 | ALLR |
| 54.6 | 52.0 | 50.2 |
Conclusion
This post aimed at formalizing an old problem in Credit Scoring, providing a literature review as well as a research idea for future work. As is often the case, practitioners have had good intuitions to deal with practical and theoretical requirements, such as performing clustering techniques, choosing segments empirically from the resulting visualization and fitting logistic regression on these.
However, situations can easily be imagined where such practices can fail, which is why other existing methods, that take into account the predictive task, were exemplified. Nevertheless, as in the best case scenario, practitioners would like to have an all-in-one tool that works with missing values and eventually performs quantization and interaction screening while guaranteeing the best predictive performance by embedding the learning of a segmentation in the predictive task of learning its logistic regression, a new method is proposed, based on an SEM algorithm, that was adapted to be usable with the glmdisc method developed in earlier posts.
On simulated data, it shows very promising results that aims at demonstrating the consistency of the approach. On real data from CACF, other methods yielded disappointing results while glmtree-SEM was able to compete with the current performance which required months of manual adjustments. By adding the quantization and interaction screening ability to this algorithm, as described in Section 1.5, we could easily imagine beating this ad hoc segmentation by a significant margin.
©2009 IEEE↩
| [1] | Michael I Jordan and Robert A Jacobs. Hierarchical mixtures of experts and the em algorithm. Neural computation, 6(2):181-214, 1994. [ bib ] |
| [2] | David Opitz and Richard Maclin. Popular ensemble methods: An empirical study. Journal of artificial intelligence research, 11:169-198, 1999. [ bib ] |
| [3] | Jérôme Pagès. Multiple factor analysis by example using R. Chapman and Hall/CRC, 2014. [ bib ] |
| [4] |
Sébastien Lê, Julie Josse, and François Husson.
Factominer: An r package for multivariate analysis.
Journal of Statistical Software, Articles, 25(1):1-18, 2008.
[ bib |
DOI |
http ]
In this article, we present FactoMineR an R package dedicated to multivariate data analysis. The main features of this package is the possibility to take into account different types of variables (quantitative or categorical), different types of structure on the data (a partition on the variables, a hierarchy on the variables, a partition on the individuals) and finally supplementary information (supplementary individuals and variables). Moreover, the dimensions issued from the different exploratory data analyses can be automatically described by quantitative and/or categorical variables. Numerous graphics are also available with various options. Finally, a graphical user interface is implemented within the Rcmdr environment in order to propose an user friendly package. Keywords: |
| [5] | Ludovic Lebart, Alain Morineau, and Marie Piron. Statistique exploratoire multidimensionnelle, volume 3. Dunod Paris, 1995. [ bib ] |
| [6] | Svante Wold, Arnold Ruhe, Herman Wold, and WJ Dunn, III. The collinearity problem in linear regression. the partial least squares (pls) approach to generalized inverses. SIAM Journal on Scientific and Statistical Computing, 5(3):735-743, 1984. [ bib ] |
| [7] | William Robson Schwartz, Aniruddha Kembhavi, David Harwood, and Larry S Davis. Human detection using partial least squares analysis. In 2009 IEEE 12th International Conference on Computer Vision (ICCV), pages 24-31. IEEE, 2009. [ bib ] |
| [8] | Eric Bair, Trevor Hastie, Debashis Paul, and Robert Tibshirani. Prediction by supervised principal components. Journal of the American Statistical Association, 101(473):119-137, 2006. [ bib ] |
| [9] | Kin-Yee Chan and Wei-Yin Loh. Lotus: An algorithm for building accurate and comprehensible logistic regression trees. Journal of Computational and Graphical Statistics, 13(4):826-852, 2004. [ bib ] |
| [10] | Leo Breiman, J. H. Friedman, R. A. Olshen, and C. J. Stone. Classification and Regression Trees. Statistics/Probability Series. Wadsworth Publishing Company, Belmont, California, U.S.A., 1984. [ bib ] |
| [11] | Niels Landwehr, Mark Hall, and Eibe Frank. Logistic model trees. Machine learning, 59(1-2):161-205, 2005. [ bib ] |
| [12] | Jerome Friedman, Trevor Hastie, Robert Tibshirani, et al. Additive logistic regression: a statistical view of boosting (with discussion and a rejoinder by the authors). The annals of statistics, 28(2):337-407, 2000. [ bib ] |
| [13] | J Ross Quinlan. C4. 5: programs for machine learning. Elsevier, 2014. [ bib ] |
| [14] | Marc Sumner, Eibe Frank, and Mark Hall. Speeding up logistic model tree induction. In European Conference on Principles of Data Mining and Knowledge Discovery, pages 675-683. Springer, 2005. [ bib ] |
| [15] | Achim Zeileis, Torsten Hothorn, and Kurt Hornik. Model-based recursive partitioning. Journal of Computational and Graphical Statistics, 17(2):492-514, 2008. [ bib ] |
| [16] | Torsten Hothorn, Kurt Hornik, and Achim Zeileis. Unbiased recursive partitioning: A conditional inference framework. Journal of Computational and Graphical statistics, 15(3):651-674, 2006. [ bib ] |
| [17] | John Platt et al. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. Advances in large margin classifiers, 10(3):61-74, 1999. [ bib ] |
| [18] | Bianca Zadrozny and Charles Elkan. Transforming classifier scores into accurate multiclass probability estimates. In Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining, pages 694-699. ACM, 2002. [ bib ] |
| [19] | Hastie, T., Tibshirani, R., Friedman, J., & Franklin, J. The elements of statistical learning: data mining, inference and prediction In The Mathematical Intelligencer, 2005. |
| [20] | Dempster, A. P., Laird, N. M., & Rubin, D. B. Maximum likelihood from incomplete data via the EM algorithm. In Journal of the Royal Statistical Society: Series B (Methodological), 39(1), 1-22. 1977. |